[논문 리뷰] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
논문 링크 : arxiv.org
안녕하세요, 기술적 성장을 이루고 계시는 엔지니어, 개발자, 리서처 분들께 인사드립니다!
이번 논문은 최근에 핫한 AI 모델인 DeepSeek-R1, DeepSeek-R1-Zero에 대해 다룹니다. 이 모델들은 강화 학습을 기반으로 하여, 적은 양의 지도 학습 데이터를 활용했음에도 뛰어난 추론 성능을 보여주고 있는 것이 특징입니다. 또한 다양한 크기를 가진 오픈소스 버전도 제공하여 실제 적용 가능성을 확장하고 있습니다.
AI, LLM 연구 및 개발, 또는 자연어 처리나 강화학습 분야에 관심이 있으신 분들에게 도움이 되었으면 좋겠습니다. 본 리뷰 글을 통해 딥시크의 자세한 내용을 숙지하고, 어떻게 강화학습을 통해 AI의 잠재력을 극대화할 수 있는지에 대한 통찰을 얻으셨음 좋겠습니다. 간단한 느낀 점 이후에 자세한 논문 요약이 펼쳐질 예정이니, 즐겁고 유익한 읽기 되시길 바랍니다:)
내가 느낀 점
1. 강화학습의 중요성
이 논문은 강화학습(RL)의 핵심적인 역할을 강조합니다. 특히 SFT(지도 미세조정) 없이도 RL만으로 모델 성능을 획기적으로 향상시킨 점이 인상적이었습니다. RL이 다양한 과제에서 매우 중요한 역할을 할 수 있음을 다시 한 번 입증하는 사례로, 앞으로 RL의 가능성에 대한 기대가 커졌습니다.
2. 기업에서의 활용을 시도하기 위해 모델 증류가 좋긴 하지만, 한국어 성능은 아직인 듯 하다.
대형 모델의 성능을 작은 모델로 증류할 수 있다는 점이 주목할 만합니다. 이를 통해 상대적으로 적은 자원으로도 강력한 성능을 구현할 수 있다는 가능성을 열어줍니다. 특히 경제적이고 효율적인 접근법이라는 점에서 상용화 측면에서 매우 중요한 장점으로 다가왔습니다. 그러나 현재 한국어 성능에 대한 아쉬움은 한국어 특화 데이터나 모델 구조의 개선이 필요함을 시사합니다. 이 부분에서 앞으로 추가적인 개선이 필요하다고 느꼈습니다. 현재로서 저는 영어 응답을 그대로 사용하거나, 후처리를 통해 한국어 번역을 시도해보려 합니다.
3. "아하 모멘트"의 중요성
모델이 자발적으로 고급 추론 전략을 발견하며 스스로 발전하는 순간인 "아하 모멘트"에 대한 부분이 흥미로웠습니다. 외부 조건에서 특별히 강제하지 않았음에도 이러한 행동 패턴이 자연스럽게 출현한 것이 신기했으며, 인공지능 시스템의 지능을 새로운 수준으로 끌어올릴 수도 있겠다는 생각이 들었습니다.
4. 한계점과 해결 방안
모델이 추론 과정에서 가독성이 떨어지거나 언어 혼합 문제를 겪는 점은 실용성에 있어 큰 장애물이 될 수 있습니다. 논문에서는 이를 해결하기 위한 몇 가지 접근 방안을 제시하고 있습니다. 언어 일관성을 위한 보상 시스템 도입이나, 인간의 선행 지식을 반영한 데이터 구성 등이 있었습니다.
5. 향후 연구 방향
이 논문의 마지막에, 향후 연구 방향에 대한 내용을 담고 있습니다. 특히, 소프트웨어 공학 작업에서의 효율성을 높이기 위한 Rejection Sampling 방법과 같은 전략은 제품화 과정에서 중요한 방향성을 제공한다고 생각합니다. 또한, 일반적인 능력 강화를 위한 연구와 언어 혼합 문제를 해결하기 위한 노력이 향후 모델의 성능을 더욱 향상시킬 것이라 기대됩니다.
총평:
이 논문은 기존에 없던 새로운 학습 방법론을 활용하지는 않았지만, 최신 LLM의 훈련 방식과 성능에 대한 깊은 통찰을 제공합니다. 강화학습과 모델 증류의 잠재력을 잘 활용하는 방식이 인공지능 연구 및 상용화에 큰 기여를 할 수 있다는 점을 시사하기에, 매우 뜻깊은 논문이라고 생각합니다.
다음은 논문 내용 부분입니다. 준비되셨다면, 지금부터 DeepSeek의 흥미로운 세부 사항을 함께 살펴보겠습니다!
Abstract
- DeepSeek-R1-Zero: Supervised Fine-Tuning 없이 대규모 강화 학습으로 학습된 모델. 강력한 추론 능력을 보여주지만, 가독성 문제와 언어 혼합 문제를 겪음.
- DeepSeek-R1: DeepSeek-R1-Zero의 문제를 해결하기 위해 다단계 훈련과 cold-start 데이터를 추가하여 추론 성능을 향상시킨 모델. OpenAI-o1-1217과 유사한 성능을 달성.
- 오픈소스 제공: DeepSeek-R1-Zero, DeepSeek-R1, 그리고 DeepSeek-R1에서 증류된 6개의 밀집 모델(1.5B, 7B, 8B, 14B, 32B, 70B)을 Qwen과 Llama 기반으로 오픈소스로 공개.
- 벤치마크 성능

Introduction
- DeepSeek-V3-Base를 베이스 모델로 사용하며, GRPO를 RL 프레임워크로 사용 → 모델 reasoning 성능의 핵심이 되는 프레임워크
- 수천 번의 RL steps끝에, DeepSeek-R1-Zero는 reasoning 벤치마크 성능에서 엄청난 성능을 보여줌
- DeepSeek-R1-Zero : Poor Readability, Language Mixing 부분에서 어려움을 겪음
- 이런 이슈를 해결하고 강화한 것이 DeepSeek-R1:
- 적은 양의 cold-start 데이터와, multi-stage Training Pipeline를 합쳐서 만듬
- 탄생 과정
- DeepSeek-V3-Base 파인튜닝을 위한 수천개의 cold-start 데이터 수집
- reasoning-oriented RL 수행(like DeepSeek-R1-Zero)
- RL 프로세스에서 수렴에 가까워지면, RL 체크포인트에서 기각 샘플링으로 SFT 데이터 생성(combined with supervised data from DeepSeek-V3 in domains such as writing, factual QA, and self-cognition)
- 그 데이터로 DeepSeek-V3-Base 모델 재학습
- 이후 additional RL process (모든 시나리오에서의 프롬프트 고려)
→ 주로 강화학습이 메인이고, 최소의 SFT를 활용
- distilled Qwen and Llama를 오픈소스화 → 특히 14B 모델들은 오픈소스 SOTA
1.1. Contributions
Post-Training: Large-Scale Reinforcement Learning on the Base Model
- SFT에 의존하지 않고 RL을 직접 베이스 모델에 적용함으로써, 모델이 복잡한 문제를 해결을 위한 CoT를 탐구하게 됨 → R1-Zero
- 이 돌파구가 이 분야의 미래 발전의 길을 열어줄 것임
→ 확실히 강화학습 위주의 적용이 동일 성능 대비 리소스도 줄여주고, 새로운 방법론을 제시하고 있다는 생각이 듬
- 2개의 RL stages + 2개의 SFT stages로 구성
- RL : 개선된 추론 패턴 발견 + human 선호에 맞추기
- SFT : 모델의 추론 + 비추론 능력의 시드 역할 수행
Distillation: Smaller Models Can Be Powerful Too
- 큰 모델의 추론 패턴이 작은 모델에 distilled 될 수 있음을 입증함
- DeepSeek-R1에 의해 생성된 추론 데이터를 활용해서, 몇 개의 dense 모델을 파인튜닝 → Qwen, Llama 등 / o1-mini와 비교가능한 성능 달성
- 1.5B, 7B, 8B, 14B, 32B, and 70B 체크포인트 공개(based on Qwen2.5 and Llama3)
→ (논문 외, 개인 실험) 7B, 8B를 ollama에서 사용했을 때, 한국어를 잘 못해주는 걸 발견했음

1.2. Summary of Evaluation Results
- Reasoning Tasks
- Knowledge
- Others
→ 대체로 OpenAI-o1-1217 과 동등하거나 보다 뛰어나다는 점이 핵심이라고 해석(조금 떨어지는 부분도 있음)
2. Approach
2.1. Overview
- cold-start로 SFT가 아예 없이, large-scale RL로 추론능력 향상이 가능함을 보여줬음
- 두 가지를 선보일 예정
- DeepSeek-R1-Zero : SFT data 없이 RL을 다이렉트로 모델에 적용
- DeepSeek-R1 : 수천개의 long CoT examples로 파인튜닝된 체크포인트에 RL 적용
- small dense models : R1을 작은 모델들에게 distill
→ 기대됨. RL을 어떻게 하는 지, CoT 데이터를 어떻게 만들었는 지를 핵심적으로 볼 예정
2.2. DeepSeek-R1-Zero: Reinforcement Learning on the Base Model
2.2.1. RL Algorithm
- GRPO : Group Relative Policy Optimization
- 강화 학습의 훈련 비용 절감을 위해 사용
- 그룹 점수(group scores)를 활용하여 기준(baseline)을 추정
- 질문 q에 대해 이전 정책(πθold)에서 출력 그룹 {o1 ~ oG} 샘플링 후, 목적 함수를 최대화하도록 정책 모델(πθ)을 최적화 함

-
- KL 발산( DKL )을 사용하여 정책이 참조 정책(𝜋𝑟𝑒𝑓)과 너무 많이 벗어나지 않도록 제한함
- 여기서 𝜖과 𝛽는 하이퍼파라미터이며, 𝐴𝑖는 그룹 내 보상 값 { 𝑟1 , 𝑟2 , … , 𝑟𝐺 } 을 사용하여 계산된 advantage를 나타냄

2.2.2. Reward Modeling
- Reward는 모델이 학습하는 방향을 결정하는 핵심 신호를 의미
- 논문에서는 DeepSeek-R1-Zero 훈련을 위해 rule-based 보상 시스템을 채택했고, 두 가지 유형의 reward로 구성
- Accuracy rewards : 응답이 올바른지 여부를 평가
- Format rewards : 모델의 생각하는 과정(Reasoning Process)을 특정 형식으로 표현하도록 강제하는 역할
- process neural reward model을 사용하지 않은 이유
- 보상 해킹(Reward Hacking) 문제 발생 가능성
- 대규모 강화 학습 과정에서 모델이 보상을 왜곡하여 학습할 위험
- → 모델이 보상만 최대로 받을 수 있는 방식으로 편향될 가능성이 있음.
- 추가적인 학습 자원으로 인해 Training Pipeline이 복잡해짐
- 보상 해킹(Reward Hacking) 문제 발생 가능성
2.2.3. Training Template
- DeepSeek-R1-Zero를 학습시키기 위해, 논문에서는 Base Model이 지정된 지침을 따르도록 유도하는 단순한 템플릿(Straightforward Template)을 설계함.
- 구조적인 형식만 제한
- 모델이 생성하는 출력의 구조를 추론 과정 + 최종 정답으로 제한.
- 하지만, 어떤 문제 해결 전략을 사용해야 하는지 강제하지 않음.
- 모델의 자연스러운 학습 과정 관찰 가능
- 강화 학습(RL) 진행 과정에서, 모델이 스스로 발전하는 모습을 객관적으로 관찰 및 평가 가능.
- 특정한 사고방식이나 전략을 주입하지 않음으로써, 모델이 자율적으로 문제 해결 능력을 학습하도록 유도.
2.2.4. Performance, Self-evolution Process and Aha Moment of DeepSeek-R1-Zero
1. 성능(Performance)
- DeepSeek-R1-Zero의 학습 성능은 AIME 2024 벤치마크를 기준으로 평가되며, Figure 2에서 강화 학습(RL) 진행 과정에서의 성능 향상 추이를 확인할 수 있음.

-
-
- 특히, pass@1 점수가 눈에 띄게 향상됨(15.6% → 71.0%)
- → OpenAI-o1-0912 모델(74.4%)에 필적하는 성능
- RL을 통한 강력한 추론 능력을 갖추었으며, SFT 없이도 효과적으로 학습 할 수 있음을 입증함.
-
2. 자기 진화 과정(Self-Evolution Process)
- RL 학습이 진행됨에 따라 평균 Response Length가 점진적으로 증가함 (Figure 3 참고)
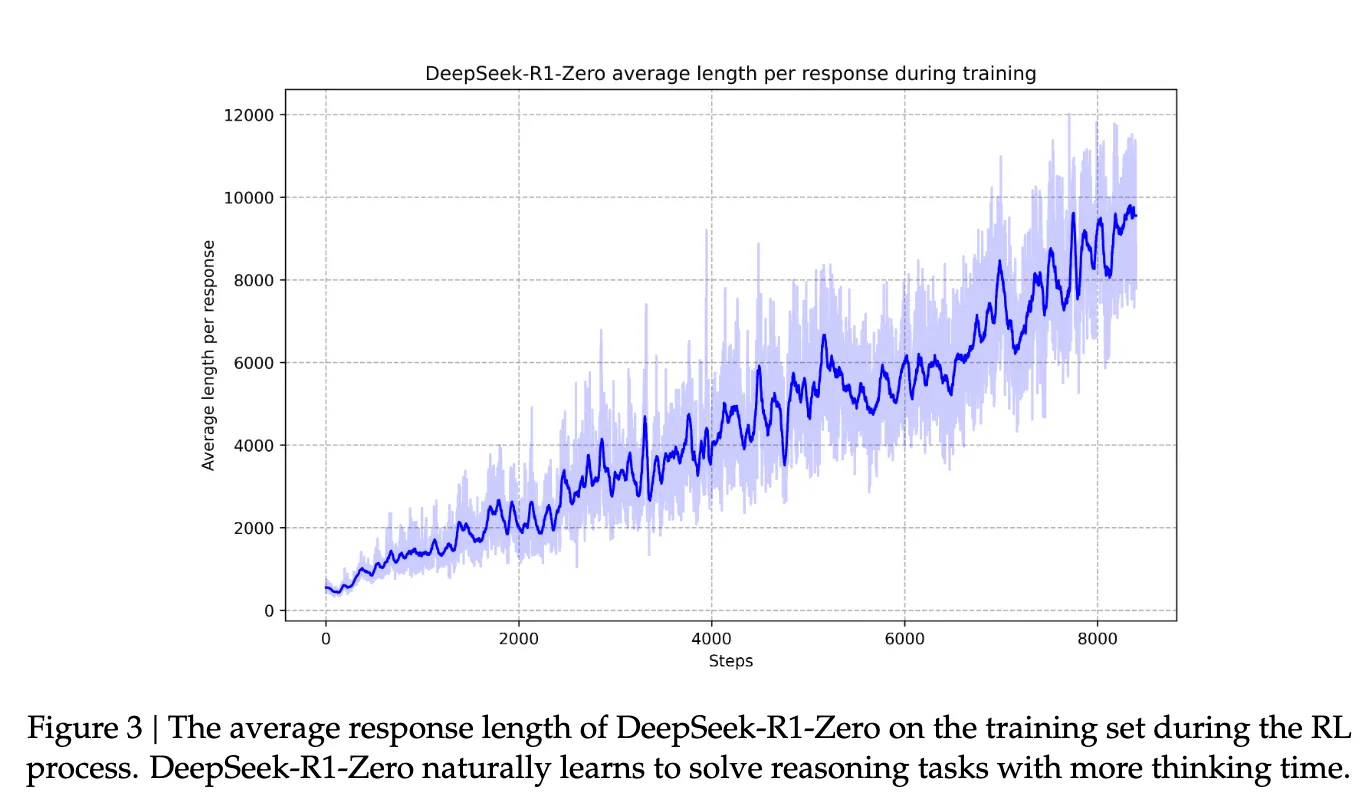
- 강화 학습 과정에서 자발적으로 고급 추론 전략을 학습했음 → 외부에서 강제하지 않았음에도 이러한 행동 패턴이 자연스럽게 출현한 것이 특징.
- 반성적 사고(Reflection) 등장
- 이전 계산 과정을 되돌아보고, 오류를 감지하여 수정하는 능력 학습
- 대체 접근법(Alternative Approach) 시도
- 같은 문제에 대해 다양한 해결 방법을 탐색하는 행동 출현
- 더 깊은 연산 활용(Extended Computation Time)
- 테스트 시점에서 더 많은 계산을 수행하여 문제를 더 정밀하게 해결
- 반성적 사고(Reflection) 등장
3. Aha Moment
- DeepSeek-R1-Zero의 학습 과정에서 특정 시점에 "아하 모멘트"가 발생
- 모델이 추론 과정에서 스스로 패턴을 깨닫고, 이를 개선하는 순간을 의미.
- 사례를 통한 aha moment 제시

4. 한계점(Drawback)
- DeepSeek-R1-Zero는 강력한 추론 능력을 갖추었지만, 몇 가지 한계를 보임.
- 가독성(Readability) 문제
- 생성된 추론 과정이 복잡하고, 가독성이 떨어지는 경우 발생
- 언어 혼합(Language Mixing) 현상
- 특정 응답에서 다른 언어가 섞여 나오는 문제 발견
→ 이를 해결하기 위해, DeepSeek-R1 모델을 개발하여 Human-Friendly 방식으로 강화 학습을 적용하는 연구를 진행 중.
2.3. DeepSeek-R1: Reinforcement Learning with Cold Start
두 가지의 이슈 발생
- 소량의 고품질 데이터를 콜드 스타트(cold start)로 도입함으로써 추론 성능을 더욱 향상시키거나 수렴 속도를 가속화할 수 있을까?
- 명확하고 일관된 사고 과정(Chain of Thought, CoT)을 생성하는 동시에 강력한 일반화 능력을 갖춘 사용자 친화적인 모델을 어떻게 훈련할 수 있을까?
→ 이에 답하기 위해 4개의 스테이지로 이루어진 DeepSeek-R1 학습 파이프라인 설계
2.3.1. Cold Start
- DeepSeek-R1-Zero에서 겪었던 RL training의 불안정한 cold start 단계를 위해, DeepSeek-R1에서는 작은 양의 long CoT data를 짜맞추어 모았음
- 모델을 초기 RL actor로 학습시키기 위함
- 몇가지의 접근법 사용
- long CoT와 함게 few-shot 프롬프팅을 example로 사용
- 직접적으로 모델에 reflection 및 verification이 포함된 상세한 답변을 생성하도록 요청
- DeepSeek-R1-Zero output을 읽기 쉽게 수집
- 결과 후처리(by human) 과정을 통해 결과를 정제
- cold-start data의 장점(DeepSeeek-R1-Zero와 비교)
- 가독성을 높인 출력 형식 설계
- |special_token|<reasoning_process>|special_token|<summary>
- reasoning_process: 추론 과정(CoT)
- summary: 결과 요약
- 잠재력
- 인간의 선행 지식을 반영하여 cold-start data를 신중하게 설계
- 가독성을 높인 출력 형식 설계
2.3.2. Reasoning-oriented Reinforcement Learning
- 미세 조정 후 RL 훈련
- DeepSeek-V3-Base를 콜드 스타트 데이터로 미세 조정한 후, 강화 학습을 통해 모델의 추론 능력을 향상시킴
- 코딩, 수학, 과학 및 논리적 추론과 같은 문제 해결에 집중
- 언어 혼합 문제: RL 훈련 중 CoT에서 언어 혼합이 발생하는 문제 발견
- 이를 완화하기 위해 언어 일관성 보상을 도입
- 목표 언어 단어 비율을 기반으로 계산되며
- → 모델의 성능에 약간의 저하를 초래하지만 읽기 쉽고 인간의 선호도에 부합
- 최종 보상
- 추론 작업의 정확도와 언어 일관성 보상을 합산하여 최종 보상을 구성 → 이를 바탕으로 RL 훈련을 진행하여 모델이 추론 작업에서 수렴하도록 진행
2.3.3. Rejection Sampling and Supervised Fine-Tuning
- 위 단계가 수렴하면, 그 체크포인트로 후속 라운드를 위한 SFT 데이터 수집 → 추론 작업 외에도 작문, 역할 수행, 번역 등 다양한 일반적인 작업을 포함
- 아래의 데이터 generate and fine-tune
- 추론 데이터(600k)
- 추론 관련 문제들(reasoning prompts)을 설정하고, 그에 대한 추론 과정(reasoning trajectories)을 생성
- 이 과정에서 rejection sampling 기법 사용→ 이전에 학습된 모델 체크포인트에서 나온 샘플을 받아들이거나 거절하는 방식으로, 품질 높은 샘플만 선택하여 수집
- 이전에는 rule-based rewards로 평가할 수 있는 데이터만 사용했으나, 이번 단계에서는 더 많은 데이터를 포함시킴
- 그 중 일부는 generative reward model을 사용하여 데이터의 질을 평가
- → 모델이 생성한 답변을 DeepSeek-V3에 입력하여 실제 정답과 모델의 예측을 비교하고, 이를 통해 보상을 계산하는 방식
- 모델이 생성하는 출력 필터링
- 여러 언어가 섞인 경우, 긴 단락, 코드 블록 등 혼란스럽고 읽기 어려운 부분
- 비추론 데이터(200k)
- DeepSeek-V3의 SFT(Supervised Fine-Tuning) 데이터셋 일부 재사용
- 일부 비추론 작업 CoT 생성
- ex : 글쓰기, 번역 문제 → 생각의 흐름을 만들고 답을 생성
- 간단한 쿼리는 CoT 없이 바로 답 생성(ex : hello)
- 일부 비추론 작업 CoT 생성
- DeepSeek-V3의 SFT(Supervised Fine-Tuning) 데이터셋 일부 재사용
- 추론 데이터(600k)
2.3.4. Reinforcement Learning for all Scenarios
- 모델의 추론 능력을 세밀하게 다듬는 2차 강화 학습 단계 진행
- 모델을 인간의 선호에 더욱 맞추기 위해 helpfulness와 harmlessness를 향상시킴
- 추론 데이터(Reasoning Data):
- DeepSeek-R1-Zero에서 제시된 방법론을 따름
- 수학, 코드, 논리적 추론 도메인에서는 rule-based rewards를 사용하여 학습 과정을 유도
- 일반 데이터(General Data):
- 복잡하고 미묘한 시나리오에서 인간의 선호를 포착하기 위해 reward models사용
- DeepSeek-V3 파이프라인을 기반으로, 선호 쌍(preference pairs)과 훈련 프롬프트 분포를 유사하게 채택
- 도움성(Helpfulness):
- 최종 요약만을 집중적으로 평가하여, 모델의 응답이 사용자의 요구에 얼마나 도움이 되는지에 중점을 둠
- 이 과정에서는 추론 과정에 방해가 되지 않도록 하여, 모델의 답변 유용성과 관련성만을 평가함
- 무해성(Harmlessness):
- 모델의 전체 응답을 평가하여, 응답에서 발생할 수 있는 위험, 편향, 또는 유해한 콘텐츠를 식별하고 이를 완화
- 추론 과정과 최종 요약을 모두 포함하여 평가함으로써 유해한 요소가 포함되지 않도록 확인
2.4. Distillation: Empower Small Models with Reasoning Capability
- 추론 능력을 더 효율적인 작은 모델에 부여하기 위해 Qwen, Llama 등 오픈소스 모델을 fine-tune
- DeepSeek-R1과 함께 curated된 800k 샘플 사용
- 이 증류 방법이 작은 모델의 추론 능력을 향상시킨다는 것을 나타냄
- RL을 일부로 포함시키지 않고 SFT만 적용
- 증류 기법의 효과를 입증하기 위함
3.Experiment
- 각종 벤치마크, 성능평가 지표가 나오는데 이해가 잘 안되어서 각각에 대해 정리를 함께 수행
벤치마크
- 길이 편향을 피하기 위해 최종 요약만을 평가에 사용
- 증류된 모델에 대해서는 AIME 2024, MATH-500, GPQA Diamond, Codeforces, LiveCodeBench에서 대표적인 결과를 보고.
- 각 벤치마크 간단 설명
- MMLU (Massive Multitask Language Understanding): 인공지능 모델이 획득한 지식을 측정하는 벤치마크
- MMLU-Redux: MMLU 변형 버전으로, 데이터 품질을 개선하고 더 공정한 평가를 제공하기 위해 설계됨
- MMLU-Pro: MMLU보다 훨씬 더 어려운 문제들로 구성된 벤치마크
- C-Eval, CMMLU, IFEval: 코드 및 수학 문제를 평가하는 데이터셋
- GPQA Diamond: 질문-응답 시스템을 평가하는 데이터셋
- SimpleQA, C-SimpleQA: 간단한 QA 문제를 평가하는 데이터셋
- SWE-Bench Verified: 소프트웨어 개발과 관련된 문제를 평가하는 벤치마크
- Aider 1, LiveCodeBench: 실시간 코드 문제 및 해결 방안을 평가
- Codeforces: 프로그래밍 경진대회 문제를 평가
- AIME 2024: 미국 초청 수학 시험을 평가하는 데이터셋
- CNMO 2024: 중국 전국 고등학교 수학 올림피아드를 평가
평가 프롬프트
- 기본 벤치마크 평가: MMLU, DROP, GPQA Diamond, SimpleQA 등은 simple-evals 프레임워크를 사용해 평가.
- MMLU-Redux: Zero-Eval 형식을 사용해 제로샷 평가 수행.
- MMLU-Pro, C-Eval, CLUE-WSC: 원래의 few-shot 프롬프트를 제로샷으로 변경해 평가.
- 기타 데이터셋: 원래 제공된 프롬프트를 그대로 사용.
- 코드 및 수학 벤치마크: HumanEval-Mul 데이터셋(8개 프로그래밍 언어) 사용, LiveCodeBench는 CoT 형식으로 평가.
- Codeforces: Div.2 문제와 전문가 설계 테스트 케이스를 사용해 평가.
- SWE-Bench: agentless 프레임워크를 사용해 결과 측정.
- AIDER 관련 벤치마크: "diff" 형식을 사용해 평가.
- 출력 제한: 각 벤치마크에 대해 DeepSeek-R1 출력은 최대 32,768 토큰으로 제한됨.
Baselines
- 기준 모델들:
- DeepSeek-V3
- Claude-Sonnet-3.5-1022
- GPT-4o-0513
- OpenAI-o1-mini
- OpenAI-o1-1217.
- OpenAI-o1-1217: 중국 본토에서 API 접근이 어려워 공식 보고서를 기반으로 성능 평가.
- 증류 모델: 오픈소스 모델인 QwQ-32B-Preview(Qwen, 2024a)와 비교
Evaluation Setup
- 최대 생성 길이: 모델의 생성 길이를 32,768 토큰으로 설정.
- 평가 방식: pass@𝑘 평가 방식 사용. 각 질문에 대해 여러 응답을 생성하여 정확도를 평가.
- 샘플링 tempetature는 0.6, top-p 값은 0.95로 설정.
- pass@1은 k개의 응답 중 첫 번째 응답이 맞을 확률로 계산됨.
3.1. DeepSeek-R1 Evaluation
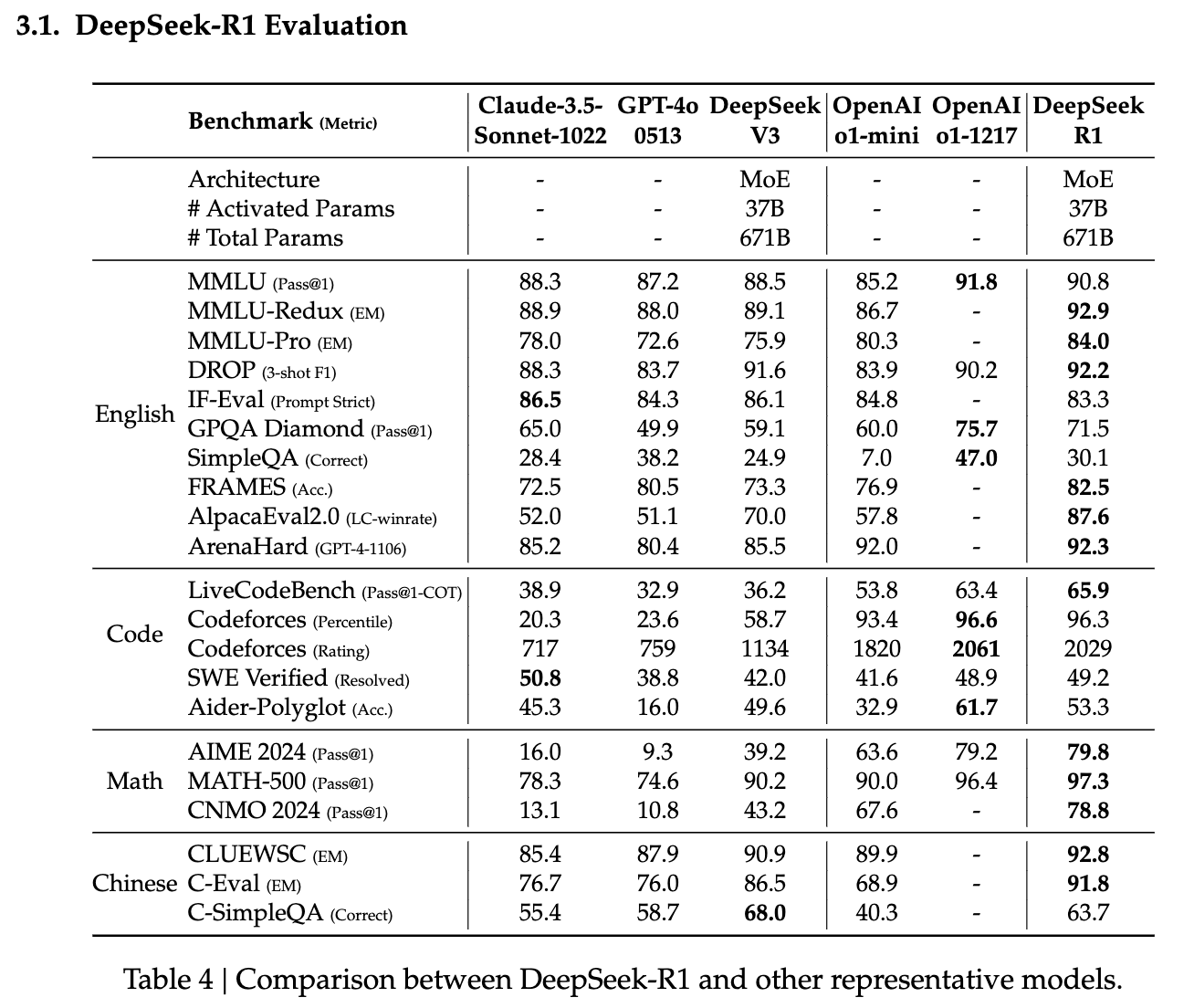
- DeepSeek-R1은 여러 분야에서 강력한 성과를 나타내고 있음
- 특히 교육적 QA 태스크, 긴 문서 분석, 수학 문제 해결에 있어서 경쟁 모델들보다 뛰어난 성과를 보임.
- 일부 코딩과 공학적 문제에서는 성과가 다소 미흡하며, 이 부분은 향후 개선 가능성이 큰 영역으로 판단.
- DeepSeek-V3와의 비교에서, DeepSeek-R1은 대규모 강화 학습을 통해 전반적인 성능을 크게 향상시킴.
3.2. Distilled Model Evaluation
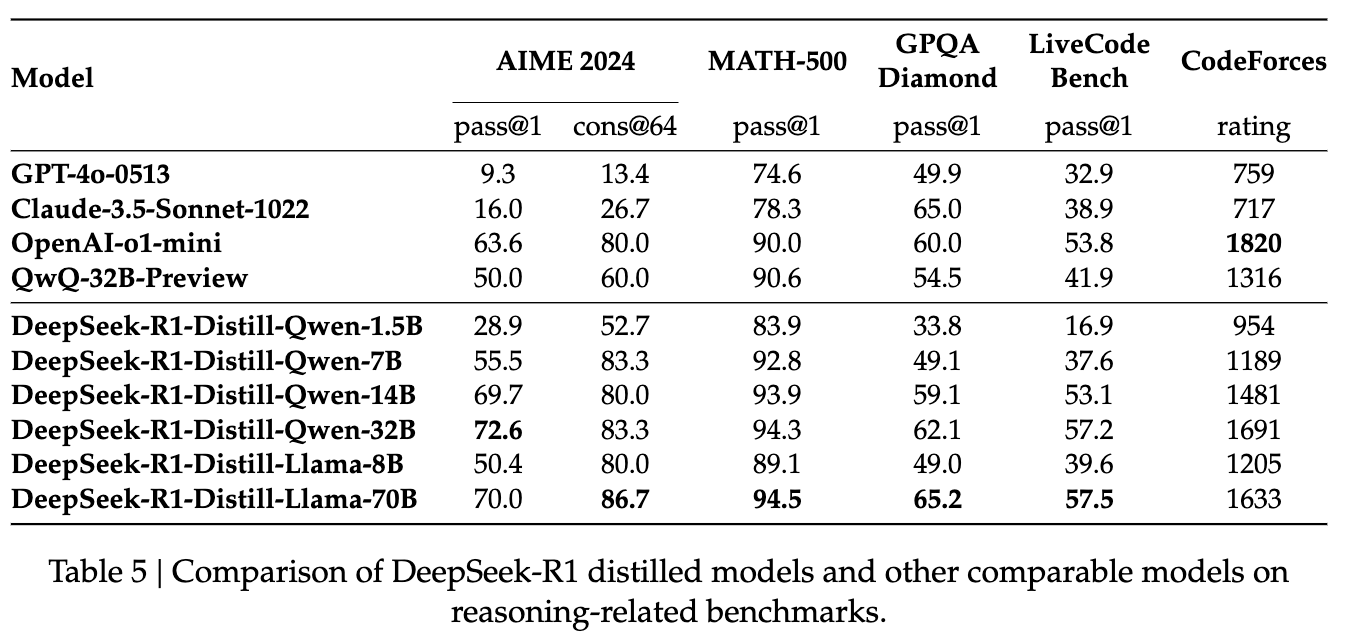
- DeepSeek-R1-14B와 DeepSeek-R1-32B, DeepSeek-R1-70B 모델들이 특히 뛰어난 성과를 보였으며, DeepSeek-R1의 출력을 증류하는 것이 추론 능력에서 크게 이점을 제공한다는 것을 확인함.
- 증류 모델에 RL을 추가적으로 적용하면 성능 향상이 더 클 것으로 보이며, 이를 더 연구할 필요성이 있다고 느낌.
4. Discussion
4.1. Distillation v.s. Reinforcement Learning
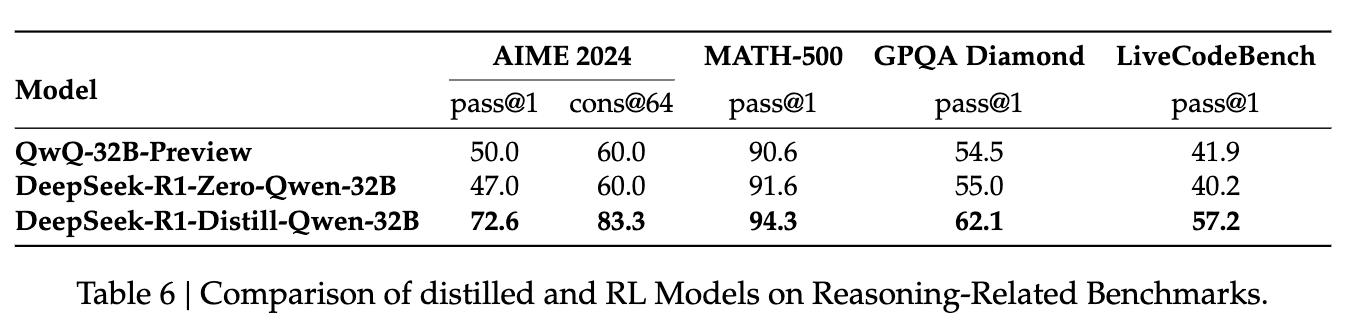
- 모델이 증류 없이, 논문에서 논의된 대규모 강화 학습(RL)을 통해 유사한 성능을 달성할 수 있는가?
- → Qwen-32B-Base에서 수학, 코드, STEM 데이터를 사용하여 10K 단계 이상을 훈련시킨 DeepSeek-R1-Zero-Qwen-32B 모델과 비교
- Distill 모델이 Zero 모델보다 모든 벤치마크에서 뛰어난 성능 → 더 강력한 모델을 작은 모델로 증류하는 것이 더 뛰어난 성능을 보임
→ 증류 전략은 경제적이고 효과적이지만, 지능의 경계를 넘어서는 발전을 위해서는 더 강력한 기본 모델과 대규모 강화 학습이 여전히 필요할 수 있음.
4.2. Unsuccessful Attempts
- DeepSeek-R1 개발 초기단계에서 겪었던 실패 경험을 공유하며 통찰을 제공하고자 함
Process Reward Model (PRM)
- 모델이 추론 과정에서 더 나은 선택을 할 수 있도록 보상을 주는 방식
- 이론적으로는 추론 성능을 향상시킬 수 있지만, 실험에서의 한계 존재.
- 한계점:
- 세밀한 단계 정의의 어려움: 추론 작업의 각 단계를 명확하게 정의하는 것이 매우 어려워, 모델이 올바른 단계를 선택하는 데 한계
- 중간 단계 검증의 어려움: 자동화된 검증 모델은 만족스러운 결과를 제공하지 못했으며, 수동 검증은 확장성에 문제를 일으킴
- 보상 해킹: 모델 기반 PRM을 사용하면 보상 해킹이 발생할 수 있으며, 이로 인해 모델을 재훈련하는 데 추가적인 리소스와 시간이 필요해 훈련 파이프라인이 복잡해짐
→ PRM은 모델의 상위 응답을 재정렬하거나 유도된 탐색을 지원할 수 있지만, 대규모 강화 학습에서의 추가적인 계산 비용을 고려했을 때 효율성이 떨어졌음
몬테카를로 트리 탐색 (MCTS)
- AlphaGo와 AlphaZero에서 영감을 얻은 방법으로, 모델이 답을 더 체계적으로 탐색할 수 있도록 돕는 트리 탐색 기법
- 모델이 해결책을 여러 단계로 나누어 해결할 수 있도록 유도
- 한계점:
- 토큰 생성의 복잡성: 체스와 달리, 모델의 답변을 토큰 형태로 생성하는 문제는 매우 방대한 검색 공간을 만들어, 모델이 효율적으로 탐색하기 어려움
- 이를 해결하고자 각 노드의 확장 한계를 설정했지만, 모델이 local optima에 갇히는 문제 발생
- value model 훈련의 어려움: MCTS는 각 단계를 안내할 value model에 의존하는데, 세밀한 value model을 훈련하는 것이 어려워서 반복적인 성능 향상이 어려웠음
- AlphaGo에서처럼 점진적인 성능 향상을 기대할 수 없었음
- 토큰 생성의 복잡성: 체스와 달리, 모델의 답변을 토큰 형태로 생성하는 문제는 매우 방대한 검색 공간을 만들어, 모델이 효율적으로 탐색하기 어려움
→ MCTS는 추론 성능을 개선할 수 있지만, value model의 품질이 매우 중요했고, 자기 탐색을 통한 성능 향상에는 여전히 큰 도전 과제가 남아 있음
5. Conclusion, Limitations, and Future Work
- DeepSeek-R1-Zero는 cold-start 데이터 없이 강화 학습을 통해 뛰어난 성능을 발휘하는 모델로, 다양한 작업에서 강력한 성과를 거두었습니다. DeepSeek-R1은 cold-start 데이터와 반복적인 RL 미세 조정을 사용하여 더욱 강력한 성능을 보입니다.
- DeepSeek-R1-Distill-Qwen-1.5B는 GPT-4o와 Claude-3.5-Sonnet을 능가하는 성능을 보이며, MATH와 AIME에서 높은 성과를 기록했습니다.
- 향후 연구 방향:
- 일반적 능력 강화: 현재 DeepSeek-R1은 DeepSeek-V3와 비교할 때 function calling, multi-turn, complex role-playing, JSON 출력에서 능력이 떨어짐. 향후 이러한 분야에서 CoT를 얼마나 길게 활용할 수 있는지를 탐구하며 개선해나가려 함.
- 언어 혼합 문제 해결: DeepSeek-R1은 중국어와 영어에 최적화되어 있지만, 다른 언어에서는 언어 혼합 문제가 발생할 수 있음. 이를 위한 향후 업데이트가 필요.
- 프롬프트 엔지니어링 개선: DeepSeek-R1은 프롬프트에 민감하여, Few-shot prompting은 성능을 저하시킴. 최적의 성능을 위해 제로 샷방식을 사용하는 것이 권장됨.
- 소프트웨어 공학 작업 효율성 향상: 현재 RL 프로세스의 긴 평가 시간으로 인해 소프트웨어 공학 작업에서 DeepSeek-R1은 큰 성과를 보이지 않았음. 거부 Rejection Sampling 기법과 Asynchronous Evaluation을 활용해 효율성을 개선할 계획임.