AI tech
밑바닥부터 시작하는 딥러닝2 정리 Chapter 2 - 자연어와 단어의 분산 표현
도리컴
2024. 4. 16. 01:48
반응형
개요
- NLP의 본질적 문제 : 컴퓨터가 우리의 말을 알아듣게(이해하게) 만들기
- 딥러닝 등장 이전의 고전적인 기법 살펴볼 예정
- 파이썬으로 텍스트 처리를 위한 사전 준비
2.1 자연어 처리란
- 자연어 처리(NLP)가 추구하는 목표 : 사람의 말을 컴퓨터가 이해하도록 만들기
- → 우리에게 도움이 되는 일을 수행할 수 있도록
- 일반적인 프로그래밍 언어는 기계적이고, 고정적임 → 딱딱한 언어
- 자연어 : 영어, 한국어 등 → 부드러운 언어 / 뜻이 애매하거나, 의미나 형태가 유연하게 바뀜
- 자연어 처리 예 : IME(입력기 전환), 문장 자동요약, 감정분석, 질의응답, 검색 엔진, 기계 번역 등
단어의 의미
- 의미의 최소 단위가 단어
- 그래서
‘단어의 의미’를 컴퓨터에게 이해시키는 것이 중요 - 세 가지 기법
- 시소러스 기법 - 유의어 사전
- 통계 기반 기법 - 통계 정보로부터 단어 표현
- 추론 기반 기법(word2vec) (다음 장에 다룸) - 신경망을 활용한 추론
2.2 시소러스(thesaurus)
- 유의어 사전으로, ‘동의어’나 ‘유의어’가 한 그룹으로 분류되어 있음
- 단어 사이의 ‘상위, 하위’ 또는 ‘전체와 부분’ 등 더 세세한 관계 정의한 경우도 있음→ 모든 단어에 대한 유의어 집합 생성 후, 관계를 그래프로 표현하여 연결을 정의할 수 있음

- 이렇게 만든 ‘단어 네크워크’를 통해 컴퓨터에게 단어 사이의 관계를 가르칠 수 있음
WordNet
- NLP분야에서 가장 유명한 시소러스(1985부터 구축하기 시작한 전통 있는 시소러스)
- 많은 연구와 다양한 NLP 앱에서 활용
- 유의어를 얻거나
‘단어 네트워크’를 이용할 수 있음 - → 단어 사이의 유사도 구할 수 있음
- 부록 B에 파이썬 구현 맛보기 나옴(정확하게는 NLTK 모듈 활용)
시소러스의 문제점
- 사람이 이처럼 수작업으로 레이블링 하는 방식엔 결점이 따를 수 밖에 없음
시대 변화에 대응하기 어렵다.
- 없어지고, 새로 생기는 말 대응 어렵
- 의미가 변하는 언어도 있음
사람을 쓰는 비용은 크다.
- 예 : 현존하는 영어 단어 수는 1000만 개(WordNet에 등록된 단어는 20만 개)
단어의 미묘한 차이를 표현할 수 없다.
- 예 : ‘빈티지’와 ‘레트로’ → 의미가 같지만, 용법은 다름
그래서! 아래 두 기법이 나온 것 → 대량의 텍스트 데이터로부터 단어의 의미를 자동 추출!
→ 사람 개입을 최소화하고 텍스트 데이터만으로 결과를 얻어내는 방향으로 패러다임이 바뀌는 중
2.3 통계 기반 기법
- corpus(말뭉치) 등장 → NLP연구나 앱을 염두에 두고 수집된 대량의 텍스트 데이터
- 걍 텍스트 데이터지만, 여기엔 사람의 ‘지식’이 충분히 담겨있다 볼 수 있음
- 목표 : 사람의 지식이 동반된 말뭉치에서 자동으로, 효율적으로 핵심을 추출하는 것
파이썬으로 말뭉치 전처리하기
- NLP에 사용되는 유명한 말뭉치 : Wikipedia, Google News
- 여기서는 일단 문장 하나로 이뤄진 단순한 텍스트 사용
- 전처리 진행 : 텍스트 → 단어로 분할 / 단어를 → 단어 ID 목록으로 변환
단계 별 진행
text = 'You say goodbye and I say hello.'
text = text.lower()
text = text.replace('.', ' .')
text # 'you say goodbye and i say hello .'
words = text.split(' ')
words # ['you', 'say', 'goodbye', 'and', 'i', 'say', 'hello', '.']- 정규표현식(regular expression) 쓰면 더 나을 수 있음
- re.split(’(\W+)?’, text) → 단어 단위로 분할 가능
- 이제 단어 목록 형태로 이용 가능
- 이후 단어에 ID 부여, ID 리스트로 이용할 수 있도록 한 번 더 손질
- 이를 위해, 파이썬 딕셔너리 이용 → 단어, 단어ID 짝지어주기
word_to_id = {} id_to_word = {} for word in words: if word not in word_to_id: new_id = len(word_to_id) word_to_id[word] = new_id # 단어에서 ID로 id_to_word[new_id] = word # ID에서 단어로

- 단어 목록을 ID 목록으로 바꿔보기
-
import numpy as np corpus = [word_to_id[w] for w in words] # 내포(comprehension) 표기 이용 corpus = np.array(corpus) corpus # array([0, 1, 2, 3, 4, 1, 5, 6])
사전 준비 끝! → preprocess()라는 함수로 만들기
def preprocess(text):
text = text.lower()
text = text.replace('.', ' .')
words = text.split(' ')
word_to_id = {}
id_to_word = {}
for word in words:
if word not in word_to_id:
new_id = len(word_to_id)
word_to_id[word] = new_id # 단어에서 ID로
id_to_word[new_id] = word # ID에서 단어로
corpus = np.array([word_to_id[w] for w in words])
return corpus, word_to_id, id_to_word
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)- 다음 목표 : 말뭉치를 사용해서 ‘단어의 의미’ 추출하기 → 통계 기반 기법(단어를 벡터로 표현)
단어의 분산 표현
- 색 표현을 예시로 들어봄
- 코발트 블루로 표현할 수도 있지만, RGB라는 3가지 성분으로 표현도 가능
- 핵심 : RGB와 같은
벡터 표현이 색을 더 정확하게 명시할 수 있다!- 어느 색 계열인지도 한 눈에 보임 → 관련성 표현, 정량화 모두 벡터 표현이 이득
- 이처럼, ‘단어’도 벡터로 표현할 수 있다면?
- 원하는 것 : 단어의 의미를 정확하게 파악할 수 있는 벡터 표현→ 보통 고정 길이의
dense vector로 표현 함(원소가 0이 아닌 실수인 벡터) - → 이를 단어의
‘분산 표현(distributional representation)’이라 함
- 원하는 것 : 단어의 의미를 정확하게 파악할 수 있는 벡터 표현→ 보통 고정 길이의
분포 가설
- 단어를 벡터로 표현하는 수많은 연구에서 단 하나의 핵심 아이디어!
‘단어의 의미는 주변 단어에 의해 형성된다~’⇒ 이게 분포 가설(distributional hypothetis)- 단어 자체에는 의미가 없고, 그 단어가 사용된
맥락(context)이 의미를 형성!
- 맥락이라는 말을 자주 쓸 예정
- 맥락 : 특정 단어를 중심으로, 주변에 놓인 단어를 가리킬 때 쓸 거
- 예 : 윈도우 크기가 2인 context / 맥락의 크기 = 윈도우 크기

동시발생 행렬
- 분포 가설을 기반으로 단어를 벡터로 나타내보자
- 어떤 단어에서, 그 주변에 어떤 단어가 몇 번이나 등장하는지 집계
- 이를
‘통계 기반(statistical based) 기법’이라 함import sys sys.path.append('..') import numpy as nnp from commom.util import preprocess text = 'You say goodbye and I say hello.' corpus, word_to_id, id_to_word = preprocess(text) print(corpus) # [0 1 2 3 4 1 5 6] print(id_to_word) # {0: 'you, 1: 'say', 2: 'goodbye', 3: 'and', 4: 'i', 5: 'hello', 6: '.'} - you의 맥락 살펴보기(윈도우 크기 1로 정함) →
동시발생 행렬 만드는 과정 - say라는 단어 하나 뿐임→ 이렇게 되면, “you”는 [0, 1, 0, 0, 0, 0, 0]이라는 벡터로 표현

- → 이렇게 되면, “you”는 [0, 1, 0, 0, 0, 0, 0]이라는 벡터로 표현
- → “say”에 대해서도 같은 작업 수행
- 이를

-
- → 이제 모든 단어 수행 하면?
- → 모든 단어에 대해 동시발생하는 단어를 표에 정리한 것 / 각 행 : 해당 단어를 표현한 벡터

-
- → 이 표를
동시발생 행렬(co-occurrence maxrix)이라고 함
- → 이 표를
- 코드로 동시발생 행렬 만들어주는 함수 구현
- 파라미터 : 단어 ID 리스트, 어휘 수, 윈도우 크기
-
def create_co_matrix(corpus, vocab_size, window_size=1): corpus_size = len(corpus) co_matrix = np.zeros((vocab_size, vocab_size), dtype=np.int32) for idx, word_id in enumerate(corpus): for i in range(1, window_size + 1): left_idx = idx - i right_idx = idx + i if left_idx >= 0: left_word_id = corpus[left_idx] co_matrix[word_id, left_word_id] += 1 if right_idx < corpus_size: right_word_id = corpus[right_idx] co_matrix[word_id, right_word_id] += 1 return co_matrix - co_matrix를 2차원 배열로 초기화
- 모든 단어 각각에 대해, 윈도우에 포함된 주변 단어를 세어 나감
- 말뭉치가 아무리 커져도 자동으로 동시발생 행렬을 만들어 준다~
벡터 간 유사도
- 내적이나 유클리드 거리 등 다양
- 자주 이용 →
코사인 유사도 - 코사인 유사도 : 분자에는 내적, 분모에는 각 벡터의 노름(L2 norm)
- 핵심 : 벡터 정규화 + 내적 구하기
유사 단어의 랭킹 표시
- 말뭉치 크기가 너무 작으면 직관과는 거리가 먼 결과가 나옴
- 이걸로, 통계 기반 기법의 ‘기본’을 끝마침
2.4 통계 기반 기법 개선하기
- 개선 작업 + 실용적인 말뭉치를 통해 진짜 단어의 분산표현 얻어볼 예정
상호정보량
발생 횟수라는 건 사실 그리 좋은 특징이 아님- 고빈도 단어가 the, car 등 → 동시발생은 많지만, 이렇게 따지면 car은 drive보다 the와의 관련성이 강하다고 나타남
- 이 문제를 해결하기 위해
점별 상호정보량(PMI, Pointwise Mutual Information)사용 - 확률 변수 x, y에 대해 다음 식으로 정의

- → x, y를 각각 단어에 대응시키면, P(x, y) 는 동시발생 확률을 나타낼 수 있음
PMI의 문제
- 두 단어의 동시발생 횟수가 0이면, 오류(log2 0은 -무한 이므로)
- 이를 해결하기위해 양의
상호정보량(PPMI, Positive PMI)사용

PPMI에도 문제가 있음
- 말뭉치 어휘 수에 따라 각 단어 벡터 차원 수도 증가한다는 점
- 각 원소의 ‘중요도’도 낮음 → 노이즈에 약하고 견고하지 못하다~
- 이를 해결하기 위해
차원 감소수행
차원 감소
- 핵심 : 중요한 정보를 최대한 유지하면서 줄이는 것
- 데이터 분포를 고려해 중요한 ‘축’을 찾음
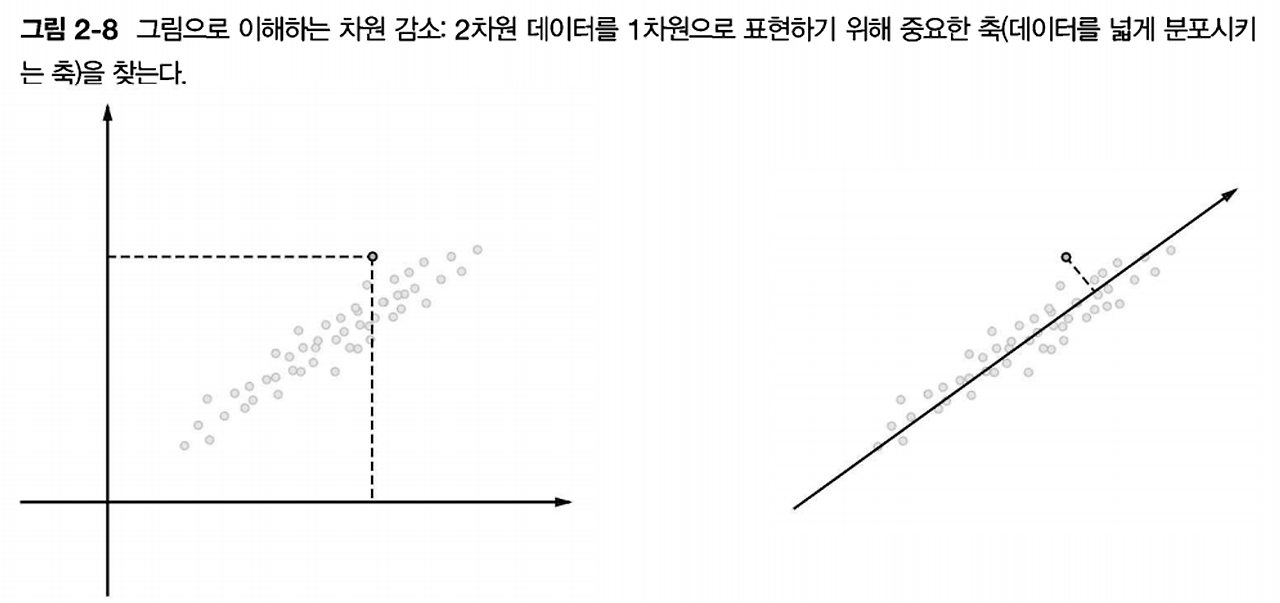
- 각 데이터점 값은 새로운 축으로 사영된 값으로 변함
- 다차원 데이터에 대해서도 수행 가능
- 우리는
특잇값분해(SVD, Singular Value Decomposition)이용 예정 - 임의의 행렬을 세 행렬의 곱으로 분해

- → U, V : 직교행렬(열벡터 서로 직교), S : 대각행렬(대각성분 외 모두 0)


SVD에 의한 차원 감소
- SVD : Singular Value Decomposition, 특잇값분해
- 냅다 코드
-
import sys sys.path.append('..') import numpy as np import matpotlib.pyplot as plt from common.util import preprocess, create_to_matrix, ppmi text = 'you say goodbye and I say hello.' corpus, word_to_id, id_to_word = preprocess(text) vocab_size = len(id_to_word) C = create_co_matrix(corpus, vocab_size, window_size=1) W = ppmi(C) # SVD U, S, V = np.linalg.svg(W) print(C[0]) # 동시발생 행렬 -> [0 1 0 0 0 0 0] print(W[0]) # PPMI 행렬 -> [0. 1.807 0. 0. 0. 0. 0. ] print(U[0]) # SVD -> [3.409e-01 -1.11e0-16 -1.205e-01 -4.441e-16 0.000e+00 -9.323e-01 2.226e-16 - → SVD에 의해 변환된 Dence vector 표현은 변수 U에 저장됨
- 밀집벡터 U의 차원을 감소시키려면? → 단순히 처음의 두 원소를 꺼내면 됨
-
print(U[0, :2])
- 각 단어를 2차원 벡터로 표현 후 그래프로 그려보기
for word, word_id in word_to_id.items(): plt.annotate(word, (U[word_id, 0], U[word_id, 1])) plt.scatter(U[:, 0], U[:, 1], alpha=0.5) plt.show()
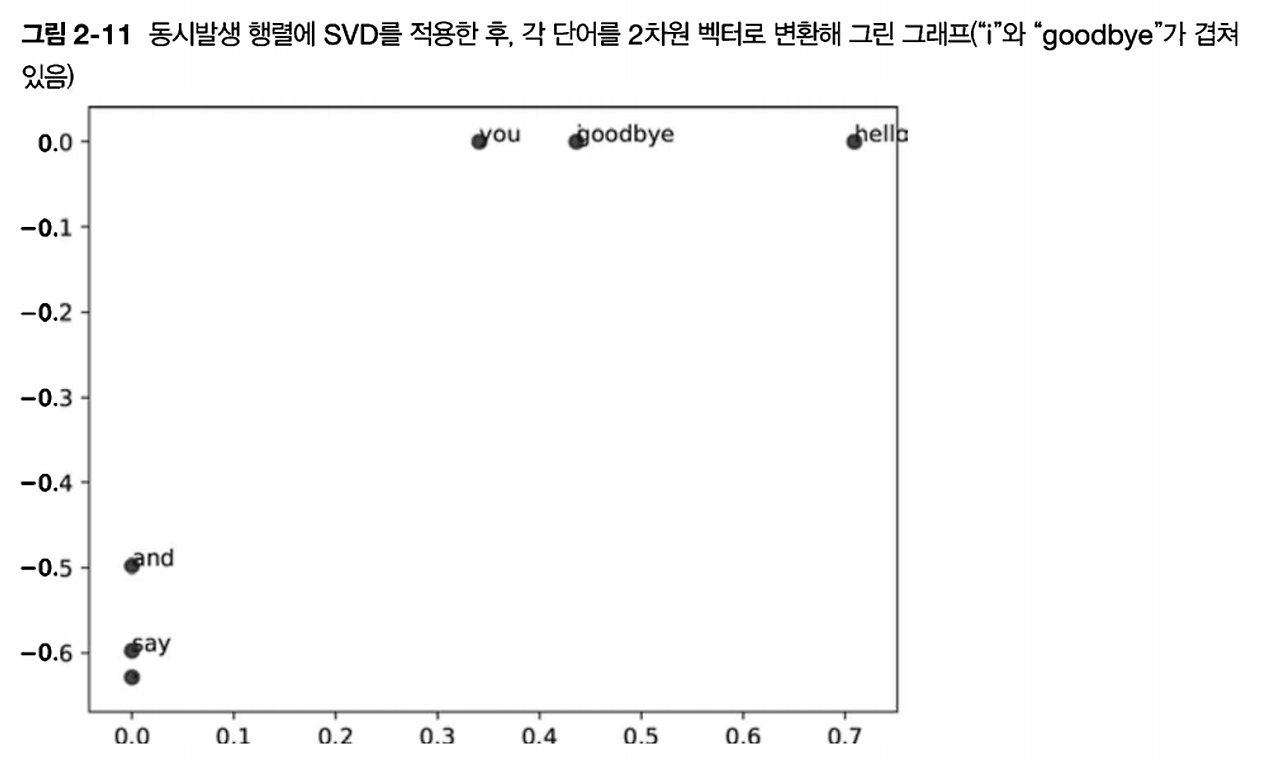
- → goodbay, hello 가까이, you, i 가까이 있음(우리의 직관과 비교적 비슷)
- PTB 데이터셋이라는 더 큰 말뭉치 사용해보자!
- 행렬크기 N에 대해, SVD 계산은 O(N^3) 걸림
- → Truncated SVD 등의 더 빠른 기법을 실제 이용함(특이값이 작은 것은 버리는 방식)
PTB 데이터셋
- 본격적인 말뭉치로 실험 시작
- 펜 트리뱅크(Penn Treebank, PTB)
- 주어진 기법의 품질 측정용 벤치마크로 자주 사용됨
- 한 문장이 하나의 줄로 저장되어 있음
- 코드 예시
-
import sys sys.path.append('..') from dataset import ptb corpus, word_to_id, id_to_word = ptb.load_data('train') # 데이터 읽어들이기 print('말뭉치 크기 : ', len(corpus)) print('corpus[:30] : ', corpus[:30]) print() print('id_to_word[0] : ', id_to_word[0]) print('id_to_word[1] : ', id_to_word[1]) print('id_to_word[2] : ', id_to_word[2]) print() print("word_to_id['car'] : ", word_to_id['car']) print("word_to_id['happy'] : ", word_to_id['happy']) print("word_to_id['lexus'] : ", word_to_id['lexus']) - 실행 결과

PTB 데이터셋 평가
- 통계 기반 기법 적용
- 고속 SVD 이용을 위해 sklearn 모듈 설치
import sys
sys.path.append('..')
import numpy as np
from common.util import most_similar, create_co_matrix, ppmi
from dataset import ptb
window_size = 2
wordvec_size = 100
corpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
print('동시발생 수 계산 ...')
C = create_co_matrix(corpus, vocab_size, window_size)
print('PPMI 계산 ...')
W = ppmi(C, verbose=True)
print('SVD 계산 ...')
try:
# truncated SVD (빠름~)
from sklearn.utils.extmath import randomized_svd
U, S, V = randomized_svd(W, n_components=wordvec_size, n_iter=5, random_state=None)
except ImportError:
# SVD (느림~)
U, S, V = np.linalg.svd(W)
word_vecs = U[:, :wordvec_size]
querys = ['you', 'year', 'car', 'toyota']
for query in querys:
most_similar9query, word_to_id, id_to_word, word_vecs, top=5)- 실행 결과

- → you를 보면, ‘i’, ‘we’가 상위(인칭대명사)
- 의미 혹은 문법적인 관점에서 비슷한 단어들이 가까운 벡터로 나타남
- → 우리의 직관과 비슷!
- 이제
‘단어의 의미’를 벡터로 인코딩하는데 성공!- 맥락에 속한 단어의 등장 횟수 셈 → PPMI 행렬로 변환
- SVD로 차원 감소 → 단어의 분산 표현(고정 길이의 밀집 벡터)
- 대규모 말뭉치를 쓰면 단어 분산 표현 품질도 더 좋아질 것임~
2.5 정리
- 컴퓨터에게 ‘단어의 의미’ 이해시키기 위주로 진행했음
- 시소러스 기법 → 통계 기반 기법 순으로 살펴봄
- 시소러스는 사람이 갈리기에 비효율적이고 표현력에 한계가 있다~
- 통계 기반 기법에 따른 분산 표현은 의미가 비슷한 단어들이 벡터공간에서도 서로 가까이 모여 있더라!
- 전처리 함수 cos_similarity(), most_similar() 함수 구현했었음 → 다음 장 이후에도 사용

반응형