안녕하세요! 이 글은 최근에 카카오에서 출시한 Kanana 언어 모델에 대한 논문을 요약한 글로, 한국어 성능에 특화된 대형 언어 모델에 관심이 있는 연구자나 개발자 분들께 인사이트가 될 것이라 생각합니다.
논문 리뷰 링크:
논문 링크 : arxiv.org
딥러닝 및 자연어 처리, LLM 분야에서 카카오가 어떤 전략을 선택했는지에 대한 유익한 내용이 담겨있으니, 꼭 한 번 확인해 보시길 권장드립니다. 모델 경량화, 비용 최적화, 사전 학습 및 후처리 기법을 활용한 최신 연구 및 기술에 관심이 있는 분들에게 유익한 정보가 되기를 기대해 봅니다. 그럼 시작하겠습니다 :)
Abstract
Kanana의 Pre/Post-training 단계에서 사용한 기술들에 대한 세부 설명 예정
- Pre-training
- high quality data filtering
- staged pre-training
- depth up-scaling
- and pruning and distillation.
- Post-training
- supervised fine-tuning
- preference optimization
+ 2.1B ~ 32.5B까지의 파라미터 범위를 가진 모델들이 있음(2.1B 공개, 한국어 언어 모델 연구 활성화 도모)
1 Introduction
- LLM이 발전되어 왔지만, cost또한 상당히 증가함
- Kanana 모델 패밀리: 낮은 연산 비용으로 SOTA 성능 유지 (2.1B, 9.8B, 32.5B)

- 효율적 학습: 3조 토큰 데이터셋, 비용 절감 기법 적용
- 최적화: 가지치기·증류 기법으로 모델 경량화
- 명령어 모델: 지도 학습·최적화로 다양한 작업 수행
- 도메인 확장: RAG, 임베딩, 함수 호출 등 적용
→ 비용과 성능의 trade-off를 어떻게 최적화했는지, 어떤 데이터 정제 과정을 거쳤는 지 위주로 논문을 살펴볼 예정
2 Pre-training
사전 학습 단계에서 비용을 줄이는데 포커스를 맞춤(2.1에서 결과 공개)
- 두 가지 enhance 전략
- data efficiency(2.2에서 공개)
- training efficiency(model scailing 관련, 2.3에서 공개)
2.1 Performance

- 평가:
- 영어/한국어 일반 지식, 코드, 수학적 추론 평가
- MMLU(영어), KMMLU·HAE-RAE(한국어), HumanEval·MBPP(코드), GSM8K(수학) 벤치마크 사용
- Kanana Flag 32.5B 성능:
- Llama 3.1 70B, Gemma 2 27B, EXAONE-3.5-32B보다 높은 성능
- MMLU, KMMLU 등 지식 기반 이해 평가에서 우수한 결과
- Llama 3.1 8B보다 적은 연산량으로 높은 효율성
- **HAE-RAE (한국어 평가)**에서 강력한 성능
- 비교 모델:
- Qwen2.5, Gemma 2, EXAONE-3.5, Aya Expanse, Llama 3.1
- EXAONE, Aya Expanse는 instruct 모델 결과만 제공 (베이스 모델 미공개)
- 결론:
- Kanana 모델은 연산 효율성을 유지하면서도 지식 이해 및 한국어 성능이 우수함
- 동급 오픈소스 모델 대비 경쟁력 있는 성능 제공
2.2 Data
- 규모: 총 3조 개 토큰(Stage1에서 2.7T, Stage2 에서 300B), 영어·한국어 bilingual 학습.
- 출처: 영어·한국어 웹, 학술, 코드, 백과사전, 인스트럭션 데이터.
- 품질 개선 단계:
- arXiv, Wikipedia 데이터 정제.(생략되거나, 일관되지 않은 paragraph 필터)
- 오픈소스 코드만 포함, 라이선스 문제 제거.
- 인스트럭션 데이터 추가로 성능 향상.
- 필터링:
- 1차: 중복 제거, 휴리스틱 필터링, PII 익명화(Personally Identifiable Information)
- 2차: 영어는 DCLM, 한국어는 FineWeb-Edu 기반 FastText 필터 적용.
- FastText 참고 : https://fasttext.cc/
- 실험 결과:
- Kanana 한국어 웹 데이터 품질, FineWeb2와 유사.
- FineWeb2 참고 : https://github.com/huggingface/fineweb-2
- Edu filter 적용 시 한국어 성능 상승.
- Kanana 한국어 웹 데이터 품질, FineWeb2와 유사.
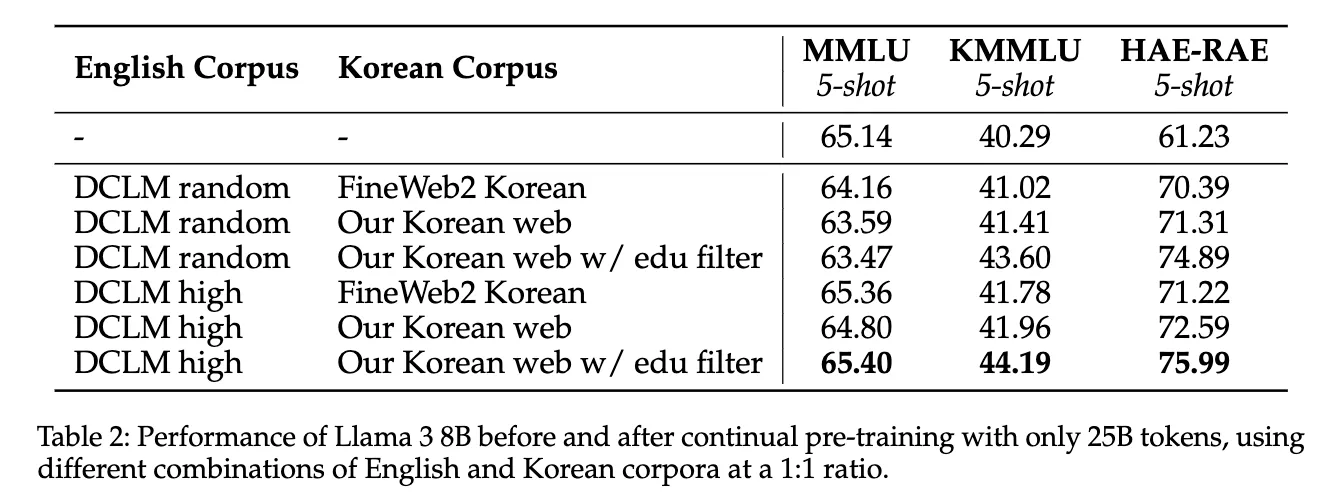
- 핵심 인사이트:
- 품질 우선 : 한국어는 양보다 질이 중요함.
- 한국어처럼 많은 토큰이 없는 언어에서는 질 높은 데이터를 우선적으로 사용하는 것이 효과적이다.
- 영어 지식 전이: 영어 품질 개선이 한국어 성능 향상에 기여함.
- 한국어 데이터 품질이 동일한 조건일 때, 영어 데이터의 품질을 높이면 한국어 관련 벤치마크에서 더 높은 점수를 얻을 수 있다.
- 품질 우선 : 한국어는 양보다 질이 중요함.
2.3 Training Process
컴퓨팅 효율성 향상을 위한 세 가지 기술:
- 단계적 사전학습: 8B 및 26.8B 모델을 단계적 프리트레이닝 방법으로 훈련.(from scratch)
- depth up-scaling: 26.8B와 8B 모델에서 Kanana Essence 32.5B 및 Kanana Flag 9.8B 모델을 확장.
- pruning and distillation: 8B 모델에서 Kanana Nano 2.1B 모델을 프루닝과 증류 기법을 사용하여 훈련 비용을 절감하고 성능을 향상시킴.
2.3.1 Staged pre-training from scratch
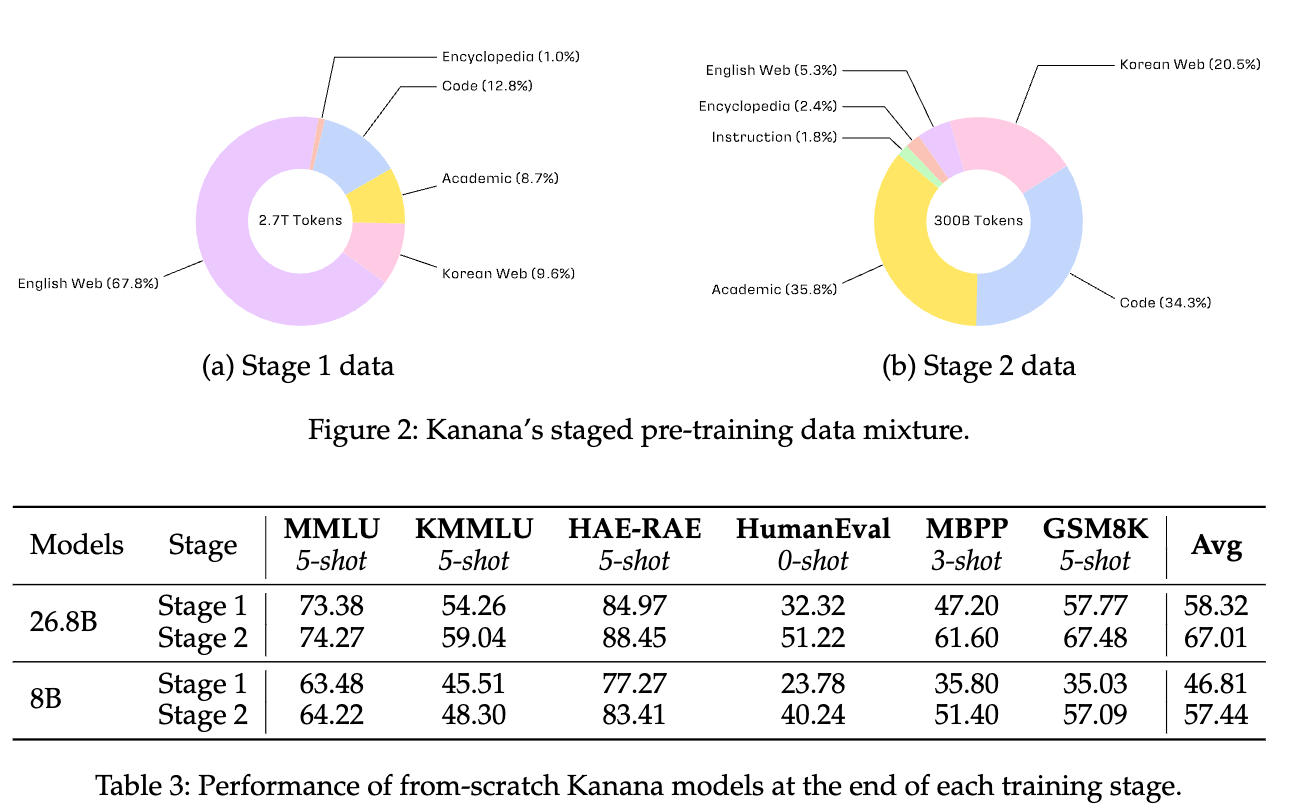
- 목표: 고정된 계산 예산 내에서 성능 최적화.
- 두 단계:
- 1단계: 8B 모델을 2.7T 보통 품질(moderate-quality) 데이터로 훈련.
- 2단계: 300B 토큰으로 모델을 추가 훈련, 고품질 데이터 비율 증가.
- 고품질 데이터 선별: 이용 가능한 high quality classifiers 활용
- 혼합 데이터 선정: 데이터 혼합 최적화 실험 및 검토 후 최적 혼합 선택.
- 효과: 2단계 최종 모델은 KMMLU에서 2.79점, 평균 성능에서 10.63점 향상.
- → stageed pre-training의 효율성을 보여줌
- 스케일 확장성: 26.8B 모델에 동일 데이터 혼합 적용 시 뛰어난 성능
2.3.2 Depth Up-scaling(DUS)
- Stacking Additional Layers
- 목표: 제한된 자원 내에서 모델 성능 향상.
- 방법: 모델에 추가 레이어를 쌓아 모델 용량 확장.
- 적용:
- Kanana 8B → Kanana Essence 9.8B
- Kanana 26.8B → Kanana Flag 32.5B
- 훈련: 동일한 데이터 혼합을 사용하여 1000억 토큰으로 각 모델을 2단계 훈련.
- 결과:
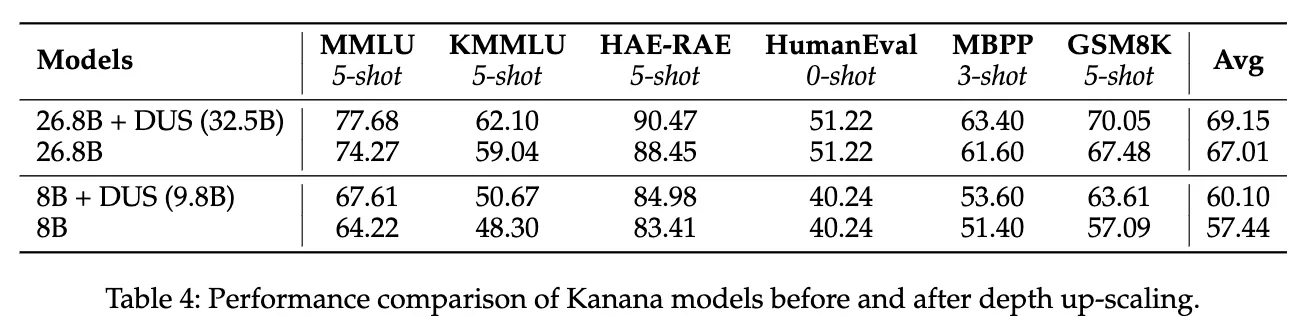
-
- Kanana Essence 9.8B: 평균 성능 57.52에서 60.12로 향상.(? Avg 잘못 쓰여 있는 것 같기도? / 57.44→60.10 으로 이해함)
- Kanana Flag 32.5B: 평균 성능 67.01에서 69.15로 향상.
- 비용 절감:
- 9.8B 및 32.5B 모델을 처음부터 훈련하는 것보다 11.06% 비용 절감.
- 전체 훈련 자원의 6.67%만 차지.
2.3.3 Pruning and Distillation
- 목표: 모델 크기를 효율적으로 축소하여 성능을 최적화.
- 방법: 8B 모델을 기반으로 pruning과 distillation을 개선한 Minitron 기법 사용.
- 효과: 모델 크기를 10분의 1로 줄이면서도 성능 향상, 훈련 데이터 크기 절감(Table 5 참조).

- 결과:
- 2.1B 모델의 경우, pruning과 distillation을 통해 성능이 향상되고, 훈련 토큰 소비가 줄어듦.
- 2.1B 모델을 두 번 이상 축소하여 KMMLU 성능을 87-99% 유지하면서 모델 크기를 50%로 줄임(Table 6 참조).

- Minitron 기법 개선:
- 목표: pruning과 distillation의 효율성 개선.
- 방법: 임베딩 채널, 피드포워드 뉴런, 어텐션 헤드를 평가하여 중요도 점수 매기기.
- 성공적인 전략:
- Layer-wise 점수 합산 방법이 성능에 중요한 영향을 미침.
- Grouped-Query Attention (GQA) 개선: 쿼리 키-값 정렬을 최적화하여 성능 향상.
- 모델 축소와 성능 비교:
- 8B 모델은 다양한 축소된 모델들과 성능 비교.
- 2.1B 모델은 50.06 점으로 가장 낮은 성능을 기록하지만, 훈련 데이터 크기와 모델 크기 절감을 고려한 효율성을 보임.
- 데이터 구성:
- 프루닝 데이터보다 증류 데이터가 성능에 더 큰 영향을 미침.
- 큰 모델에는 300억 토큰의 고품질 데이터 사용, 작은 모델은 영어 일반 도메인 데이터 비율 증가로 성능 향상.
- 결론:
- 종합적 train 전략(단계적 훈련, 깊이 확장, 반복적 pruning 및 distillation)을 통해 계산 자원을 효율적으로 사용하면서 성능이 뛰어난 모델을 생성.
- 2.1B에서 32.5B 모델까지 다양한 크기의 모델을 효율적으로 개발 성공.
3 Post-training
Kanana 모델 개발 과정에서, 자연어로 직접 상호작용을 위한 instruction-tuned 모델 개발.
- Kanana 모델 성능 강조 (Section 3.1):
- 주요 결과:
- 한국어 작업에서 우수한 성능.
- 다른 작업에서 경쟁력 있는 결과.
- 주요 결과:
- 세부 사항 (Section 3.2):
- SFT 및 선호도 데이터셋에 대한 세부 설명.
- Post-training 테크닉 (Section 3.3)
3.1 Performance
- 평가:
- 작업 범위: 대화, 지침 수행, 일반 지식, 코딩, 수학 등의 작업에서 평가.
- Korean Tasks: Kanana 모델이 LogicKor, KoMT-Bench(대화), KMMLU, HAE-RAE(지식)에서 우수한 성능을 보임.
- 다른 작업: 수학을 제외한 대부분의 작업에서 경쟁력 있는 성능.

- 성능:
- Kanana Flag 32.5B:
- Korean Chat Tasks(LogicKor, KoMT-Bench): 최고 성능.
- Korean Knowledge Tasks(KMMLU, HAE-RAE): 최고 성능.
- 9.8B, 2.1B 모델: 두 번째로 좋은 성능.
- Kanana Flag 32.5B:
→ Zero-shot CoT 방식으로 모델 성능 평가. / 기존에 학습된 내용이나 편향이 없이 모델이 고유하게 갖고 있는 능력만을 평가할 수 있음.
3.2 Data
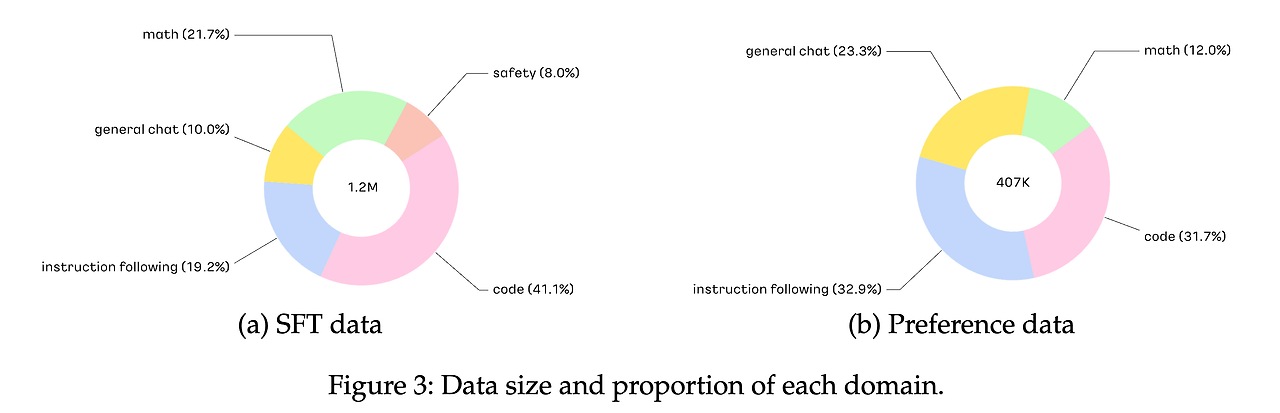
- 데이터 수집: 1.2M개의 Instruction Data 인스턴스를 영어와 한국어로 수집.
- 다양한 요구 사항 반영: 5개 주요 도메인(에 대해 데이터 수집.
- code: 492K 인스턴스
- math: 260K
- instruction following: 230K
- general chat: 120K
- safety: 96K윤리, 개인정보, 독성, 편향 관련 프롬프트 포함)
- Preference Data: 각 도메인별로 데이터를 서브 샘플링하고 균형을 맞추어 처리.
3.3 Training Process
- 다단계 후속 훈련 절차: SFT(지도학습 미세조정)와 선호 최적화 프로세스를 포함하는 다단계 후속 훈련 절차 채택.
- 3.3.1: SFT 과정의 detail.
- 3.3.2: SFT 모델에서 reward 모델을 훈련하여 선호 최적화 과정 준비.
- 3.3.3: SFT 모델에서 preference 최적화 진행, 오프라인/온라인 과정으로 구성.
→ 훈련의 각 과정에서 모델 크기별로 성능을 개선하며, 그게 수치적으로 평가됨(Figure 4)

- 훈련 과정:
- SFT 단계에서 모델은 구조화된 대화 응답을 생성하며 관련 지식을 통합하는 능력을 학습.
- Preference 최적화 단계에서는 모델의 tone and manner가 정제되어 성능이 향상됨.
3.3.1 Supervised Fine-Tuning
- SFT 과정: 구조화된 채팅 응답을 생성하고 관련 지식을 통합하는 능력을 개발.
- 데이터: 3.2에 나왔던 1.2M 개의 데이터 인스턴스를 사용하여 모델을 훈련, 각 도메인별 데이터 비율 최적화.
- 도메인 특화 데이터: 도메인 특화 데이터를 제외하면 해당 도메인 성능에 부정적인 영향을 미침.
- → 특정 도메인 데이터를 제외하더라도 다른 도메인 성능에는 영향 없음 발견(Table 9 참조).

→ 결과: 도메인별 데이터가 포함된 훈련 세트를 활용하여 각 도메인에서 균형 잡힌 성능을 유지.
3.3.2 Reward Model Training
- 후속 온라인 선호 최적화를 위한 reward 모델 훈련.
- 선호도 평가를 위해 Bradley-Terry 모델 적용.
- 훈련 데이터: 오프라인 선호 데이터와 추가적인 공공 선호 데이터를 사용
- 최적 모델: 다양한 설정에서 훈련된 reward 모델 중 가장 강력한 best-of-N 정책 성능을 보인 모델을 선택.
- best-of-N 정책 평가:
- Policy 모델에서 N개의 응답을 생성.
- Reward 모델로 응답들을 평가하고, 최고 점수를 받은 응답 선택.
- 최종 응답의 품질을 벤치마크 기준에 맞게 평가.
- 목표: 선택된 보상 모델이 온라인 선호 최적화 단계에서 응답 분포를 효과적으로 평가할 수 있도록 보장하기 위함.
3.3.3 Preference Optimization
- SFT 모델 성능 향상을 위해 선호 최적화 과정을 진행.
- 먼저 오프라인 선호 데이터를 사용해서 오프라인 선호 최적화 적용(DPO, Direct Preference Optimization)
- 오프라인 DPO 모델에서 시작하여 온라인 선호 최적화 수행.
- 응답 평가: 정책에서 생성된 응답은 reward 모델(3.3.2절에서 언급)을 사용해 평가.
- 비동기 응답 샘플링: 온라인 DPO에서 비동기식 응답 샘플링 기법을 사용
- → 반복적인 DPO로 간주할 수 있음
- 단, 이전과 달리 참조 모델을 업데이트하지 않고 오프라인 DPO 모델을 고정.
- → 이유: 참조 모델을 업데이트하면 응답 길이가 불필요하게 길어지는 경향이 있었음.
4 Adaptations
- Kanana 모델을 세 가지 인기 있는 LLM 애플리케이션에 적용:
- Embedding 모델
- Retrieval-augmented 모델
- Function calling 모델
- 실험 결과: 각 벤치마크에서 작업 특화 훈련 기법을 적용하여 Kanana 모델의 성능이 향상됨.
- 적용 가능성: 다양한 애플리케이션에 Kanana 모델을 적응시킬 수 있는 가능성 확인
4.1 Embedding Models
- 텍스트 임베딩: 텍스트의 의미를 포착하는 데 중요한 역할을 하는 밀집 벡터 표현.
- 디코더 전용 언어 모델이 LLM의 성공에 따라 문장 임베딩 모델의 주요 백본으로 자리잡음.
- Kanana 활용: Kanana Nano 2.1B를 LLM2Vec 기법을 사용하여 임베딩 백본으로 활용.
- 비교 분석: 비슷한 모델 크기를 가진 Llama 3와 Qwen2.5 모델에도 LLM2Vec을 적용하여 성능 비교.
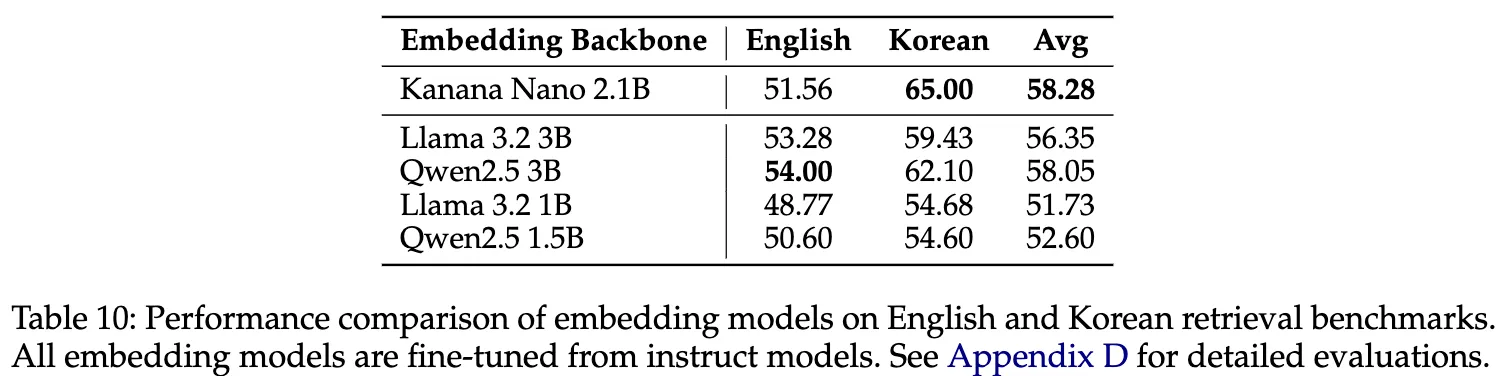
- 임베딩 모델 평가: Massive Text Embedding Benchmark (MTEB)의 하위 집합을 사용한 검색 과제 평가.
- 영어 과제: MTEB v2 리더보드에서 나온 10개의 영어 과제.
- 한국어 과제: Jang et al. (2024)에서 선정한 8개의 한국어 과제.
→ 성능: nDCG@10 점수의 평균값을 제공하여 영어와 한국어 검색 과제에 대한 결과 요약.(Table 10 참조)
- Kanana Nano 2.1B: 임베딩 작업에 효과적인 백본으로 경쟁력 있는 성능을 발휘.
- 성능 비교:
- Llama 3.2 1B, Qwen2.5 1.5B 모델을 영어와 한국어 벤치마크에서 크게 능가.
- Llama 3.2 3B, Qwen2.5 3B 모델보다 한국어 평가에서 우수한 성과.
- 영어 성과: 강력한 영어 점수와 모든 모델 중 가장 높은 평균 점수 기록.
- 결론: Kanana Nano 2.1B는 검색 작업에 최적화된 파인튜닝 시 강력한 성능을 보여줌.
4.2 Retrieval-Augmented Generation
- RAG: 대형 언어 모델이 최신 외부 정보에 접근하도록 하여, 모델 파라미터를 변경하지 않고도 사실 일관성을 유지할 수 있도록 지원.
- 추가 데이터 혼합: 사실 일관성을 보장하기 위해 모델의 grounding 능력을 훈련.
- 평가 기준:
- ContextualBench: 다중 단계 질문 응답(Multi-hop QA) 테스트.
- FACTs: 다양한 과제(추론, QA, 요약, 재작성, 추출 등) 포함.
- IFEval: 모델의 유용성 유지 평가.
- 한국어 RAG 벤치마크:
- RAG-General-Bench: 한국어의 사실 일관성 및 유용성 평가를 위한 새로운 벤치마크 개발.
- 구성: 115개의 샘플, 4개의 주요 작업 및 27개의 하위 카테고리 포함.

- 데이터셋 생성 과정(Figure 6 참조).
- 그라운딩 능력 향상: 고품질 bilingual 언어 문서를 사용해 질문-답변(QA) 쌍을 합성 생성
- 필터링: 그라운딩 점수가 낮은 인스턴스를 필터링, LLM-judge를 사용해 개선.
- SynQA-SFT: low grounding 인스턴스를 수정한 후, 이를 사용해 응답을 보강하여 SynQA-DPO라는 선호 데이터셋을 생성.
- SynQA 데이터셋과 함께,
- RAG 시나리오에서 다양한 문맥 형식과 지침을 적응하기 위해 StructLM과 FollowRAG사용.
- 1.2M개의 SFT 데이터셋을 재사용하여 훈련 중 모델의 일반 능력 저하 방지.
- SFT 및 DPO 훈련 과정에서 모델의 helpfulness 점수가 감소하는 현상 관찰됨
- 문제 해결: DPO 모델과 instruction 모델을 결합하여 helpfulness 점수 유지
- 최종 성과: Kanana Essence 9.8B RAG는 GPT-4o의 그라운딩 성능의 91.4%를 달성하면서도, instruction 모델의 helpfulness 성능을 유지 (Figure 5 참조).
4.3 Function Calling
- LLM이 외부 tool 및 데이터베이스와 상호작용하여 최신 정보를 얻는 능력.

- 한국어 데이터셋: korean-fc-corpus 생성 (영어 데이터셋을 한국어로 번역 및 맞춤형 기업 데이터셋 제작).
- 두 단계 훈련:
- 도메인 사전 학습: 여러 영어 기반 데이터셋을 사용하여 기능 호출의 기본적인 토큰 및 용어에 대해 학습.
- SFT: korean-fc-corpus를 사용해 한국어 기능 호출에 특화된 학습.
- 벤치마크: FunctionChat-Bench를 사용하여 한국어 대화형 환경에서 모델 성능을 평가.
- 단일 호출 정확도와 대화 정확도 측정.
- 비교 평가: Kanana 8B FC 모델이 GPT 모델들(gpt-4-0125-preview, gpt-4o-2024-05-13)과 비교하여 경쟁력 있는 성능을 보임 (Table 12).
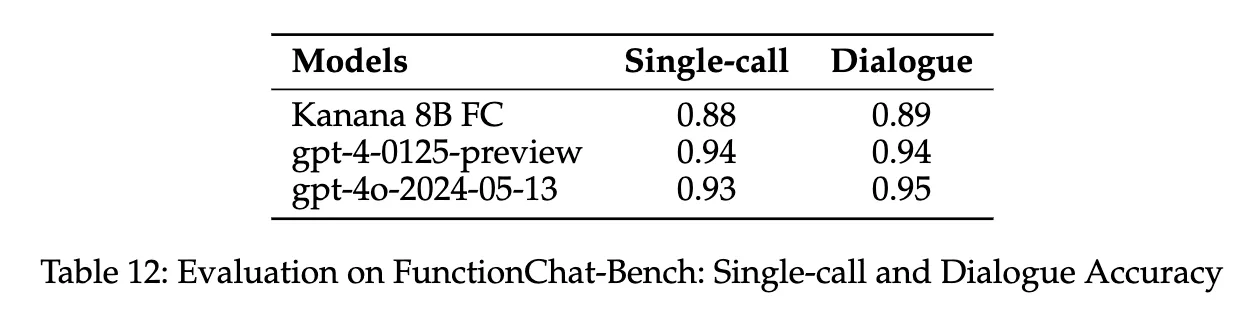
- 결론 : 중형 LLM에 대해 작업별 미세 조정을 통해 더 효율적이고 비용 절감 가능한 접근법 제공.
5 Conclusion
- Kanana 모델: 크기 {2.1B, 9.8B, 32.5B}의 LLM 시리즈로, 다른 오픈 모델들과 비교하여 비용 효율적인 훈련 절차를 강조.
- 강력한 이중 언어 능력: Kanana 모델은 KMMLU, HAE-RAE, KoMT-Bench와 같은 한국어 벤치마크에서 최고 성능을 기록하며, 다양한 영어 벤치마크에서도 경쟁력 있는 성과를 보임.
- 제한 사항: 작은 규모 모델에서의 전반적인 성능 부족, 특히 수학 분야에서의 한계.
- 향후 계획:
- 작은 모델 개선과 모든 모델의 수학 능력 향상을 위한 데이터 품질과 혼합 방법을 통한 개선.
- 비용 효율적인 훈련을 위한 전략적 접근 방식(formulating scaling laws and other training methodologies) 탐색.
- 이중 언어에서 다중 언어로 확장, 특히 덜 대표적인 언어에 대한 집중.
- 목표: 성능과 효율성의 균형을 맞추고, 모델의 언어적 범위를 넓혀 나가는 것.
Kanana 모델 개발팀:
- 앞으로도 계속해서 큰 언어 모델(Large Language Models, LLM) 분야에서 성과를 이루고자 함.
- 특히, 성능과 효율성의 균형을 맞추고, 모델의 언어적 범위를 확장하는 데 초점을 맞추고 있음
'AI tech' 카테고리의 다른 글
| 주간회고 작성 좀 해줘! : Notion + LLM을 활용한 회고 자동화 시스템 (0) | 2025.03.16 |
|---|---|
| [논문 리뷰] Kanana: Compute-efficient Bilingual Language Models (0) | 2025.03.02 |
| [논문 리뷰] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (0) | 2025.02.16 |
| [논문 리뷰] Byte Latent Transformer: Patches Scale Better Than Tokens (1) | 2025.01.19 |
| 2024 하반기 회고: Everything Everywhere All At Once (1) | 2025.01.05 |


